Building a Goodreads quote scraper
2025 January 09I’ve been wanting to code a web scraper I would actually use instead of another amazon one. Goodreads.com keeps 100 pages of random popular quotes from authors. Unfortunately there’s no data on which books they come from, but I’ll update this project if they ever add that in the future. For now, I just need functions to get a random page (1 to 100), scrape quotes from the pages, and actually extract the quote text and author.
Prerequisites: python requests: pip install requests. BeautifulSoup: pip install beautifulsoup4
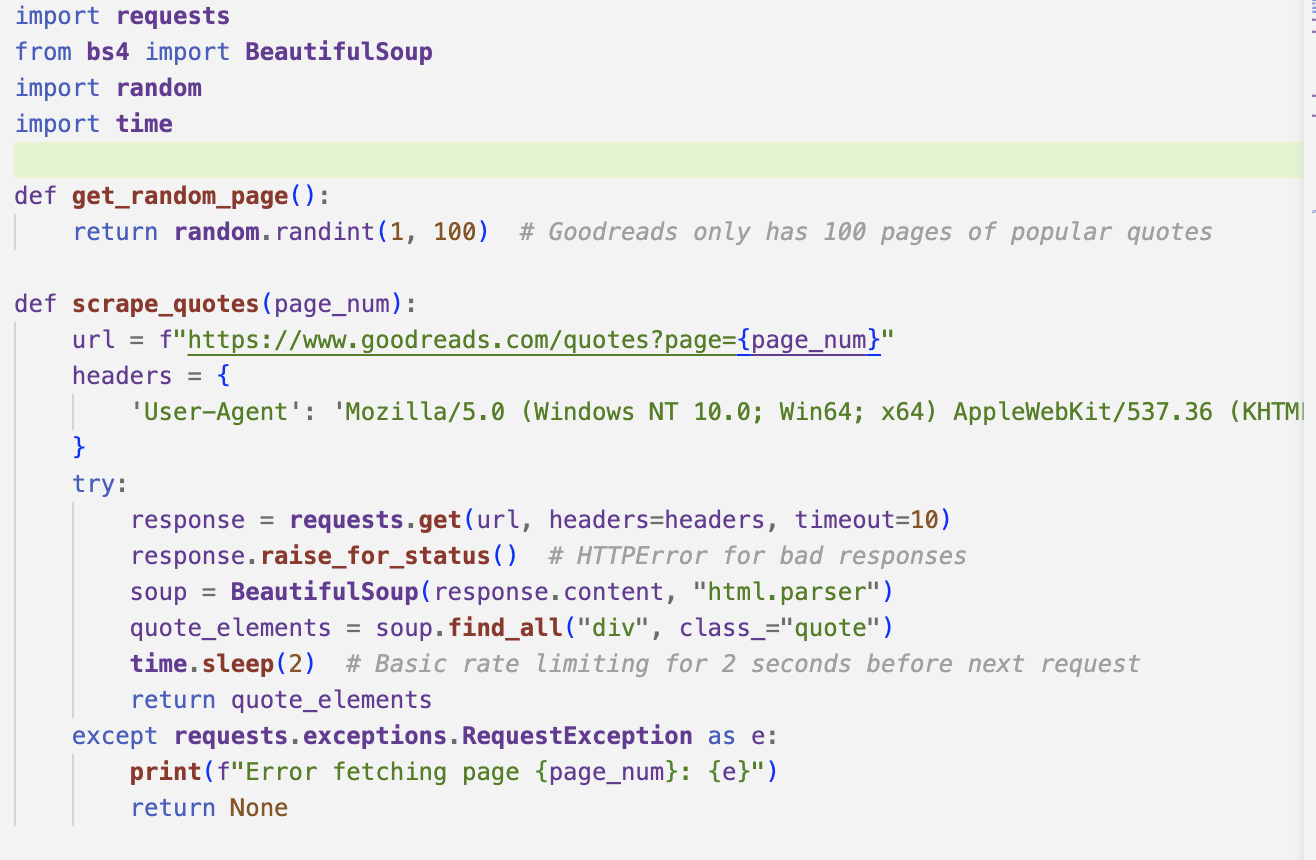
Gives you a random page number. User the requests library to extract the actual quotes and authors. User-Agent makes the requests look like a browser. Used from the examples here. time.sleep(2) so I don’t overload Goodreads. Before implementing basic rate limiting, I couldn’t extract any quotes at all 🙁

If you inspect Goodreads source code, you’ll find the quotes are inside
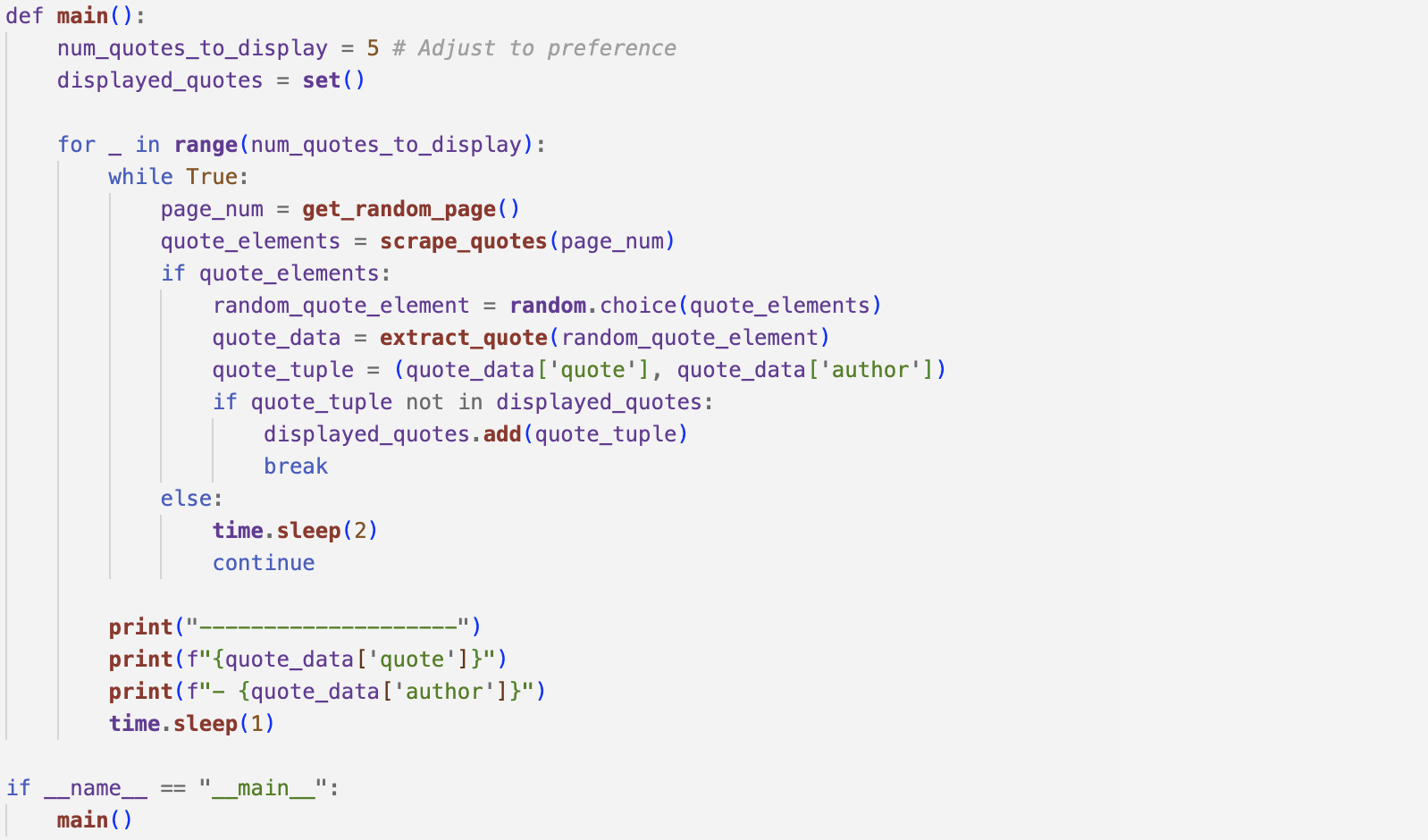
displayed_quotes prevents the same quote from displaying twice and a while True loop keeps trying to find a unique quote.
Save the script and run it from your terminal: python goodreads_quotes.py
Of course, it could be improved a lot. Another day I’ll update it to write the quotes in JSON format or possibly implement a gui.